piątek, kwietnia 28, 2017
piątek, kwietnia 21, 2017
How I saved big money for Allegro with Tibco BusinessWorks using Java
Time is money. Tibco BusinessWorks is a business enabler allowing for rapid development and very short time to market. Company which deployed Tibco EAI stack has a real market advantage. Power of now. Usage of Canonical Data Model promotes reusability. Visual programming with predefined common activities makes it easy and fast to design processes. What about complex problems which would slow down development to the left from Tibco (system calling BW services) while accessing external operations from the right, for at least 6 months. No business integration means no money. Here is the case: API of the business partner had various usage limits on different levels (including global limit). Limits were interconnected and blocking or interrupting complex business processes. Implementation of usage counters, time slots and batching among all BW clients would took one year. In fact limits were preventing business cooperation. Hey, but Tibco is a business enabler, not a blocker! BW allows to include any static Java Custom Function as internal BW function visible among built-in functions. I created "throttling" custom function holding state across component restarts in 10 minutes. Addtional 2-3 hours of development saved months of hard and complex work of BW callers! We started business cooperation much earlier and started earning money earlier. Tibco. Power of now!
Messaging of AliExpress
The biggest world global eCommerce - AliExpress has its own messaging and its source code looks interesting especially with claims "Throughout the period, 99.996% of the delay fell within 10ms, very few due to GC caused by the pause in 50ms or less, for the read and write ratio is almost balanced distributed message engine, the results are all exciting." which are about Java software.
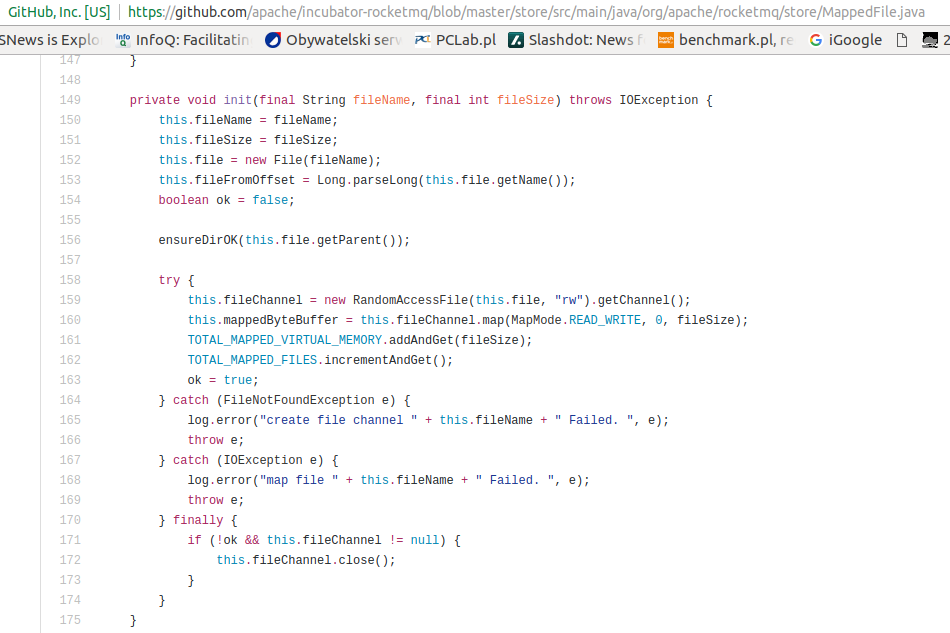
With first look following can be spotted: heavy usage of java.util.concurrent, volatile keyword, ByteBuffers and very limited usage of synchronized blocks. File storage uses plain RandomAccessFile with OS-mapped ByteBuffers where everything read and written is with computed offsets. Flushing data to disk is performed in file groups which is very wise due to mechanical sympathy with underlying disks (think about hardware I/O queues and servicing according to given offsets). Memory storage uses direct ByteBuffers not affected by GC and also locked into physical memory with POSIX mlock call. Very smart! I was exploiting the last feature while writing near RealTime software for T-Mobile emergency number. It really helps to achieve low latency without outliers.


With first look following can be spotted: heavy usage of java.util.concurrent, volatile keyword, ByteBuffers and very limited usage of synchronized blocks. File storage uses plain RandomAccessFile with OS-mapped ByteBuffers where everything read and written is with computed offsets. Flushing data to disk is performed in file groups which is very wise due to mechanical sympathy with underlying disks (think about hardware I/O queues and servicing according to given offsets). Memory storage uses direct ByteBuffers not affected by GC and also locked into physical memory with POSIX mlock call. Very smart! I was exploiting the last feature while writing near RealTime software for T-Mobile emergency number. It really helps to achieve low latency without outliers.

wtorek, kwietnia 18, 2017
czwartek, kwietnia 06, 2017
Subskrybuj:
Komentarze (Atom)

